Building a Data Web: Leveraging Knoodl for Effective Data Source Federation
Modern organizations face the daunting challenge of managing vast quantities of information from disparate sources, making accessing and analyzing it without physically moving increasingly challenging. Knoodl provides an elegant solution by enabling users to effortlessly connect data sources together – creating an effortless user experience for data consumers.
Knoodl can not only increase data accessibility but also deepen insights from various datasets. Acting as an intermediary layer among various sources, Knoodl enables users to perform complex queries instantly across disparate sources – breaking down silos that inhibit productivity while making data management simpler while opening doors for advanced analysis.
As organizations increase their dependence on data-driven decision making, platforms like Knoodl have become an essential element in providing insightful results while keeping original sources under control. We will explore how Knoodl provides organizations with a powerful data web which gives an in-depth view into their information landscape, helping inform strategic decision making based on holistic analysis.
Understanding Knoodl
Knoodl provides users with a readily accessible platform for collaboratively producing and managing data in an accessible fashion, supporting joint efforts towards building semantic applications and ontologies essential for unifying data sources across disparate sources.
RDF (Resource Description Framework) is another essential element, providing essential data regarding how resources should be represented and related. This approach assists machine-to-machine communication among different systems by sharing and interpreting data efficiently and smoothly.
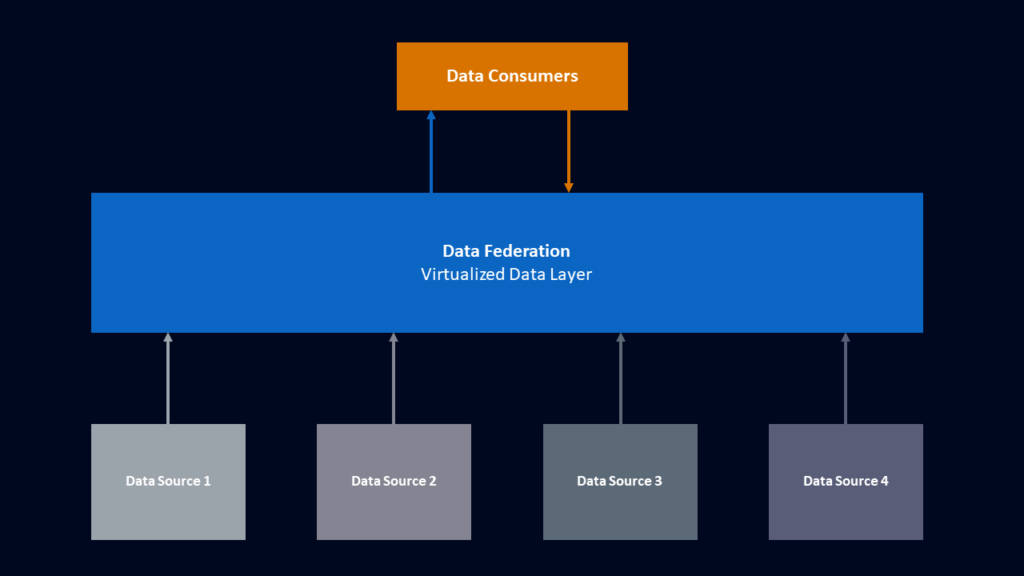
Knoodl fosters community collaboration; users can contribute to developing and enriching data sources, making it simpler for all of us to access shared knowledge. Knoodl also features its Data Web Architecture in which can also find a Data Storage Web.
Knoodl’s architecture provides a solid basis for creating a data web, featuring services built upon Java and SPARQL interfaces for dynamic interaction with user data.
Knoodl’s design promotes a decentralized data model. Instead of consolidating sources into one central repository, this arrangement permits existing ones to remain intact while offering one single entrypoint for everything that may reside therein.
Data Federation allows users to quickly run queries across multiple datasets in real-time and increase agility through local autonomy in data management, making it simpler for them to gain insights without adding complexity.
Implementation: The Basics
Data federation allows organizations to combine information from multiple sources into one centralized structure, but successful implementation requires integration between sources as well as creating clear semantic relationships among them.
Integrating various data sources is integral to successful data federation. Organizations should identify all pertinent sources – databases, APIs or file systems – before employing tools that connect these without manually moving any of the data around.
Consider these steps for success:
- Assessment: Evaluate data types and formats across each source.
- Connectivity: Utilizing APIs provided by platforms like Knoodl to connect disparate sources while aligning fields consistently for interpretive consistency across sources.
- Data Mapping: To align fields so as to guarantee proper interpretation.
- Establish Semantic Relationships. This strategy keeps data where it should be while offering real-time access and analysis – making gaining insights faster simpler.
- Set Up Semantic Filters.
Establishing semantic relations is critical in making sense of disparate data sets, with definitions and agreements among elements helping facilitate accurate interpretation.
Steps that could help establish these relationships include:
- Standardizing: Define key terms and concepts clearly to avoid any misunderstandings.
- Ontology Development: Develop an ontology framework outlining data relationships.
- Ontology Utilization: Leverage an ontology framework as context so users understand where data fits together.
- Metadata Utilization: Make use of metadata so users know exactly where their information fits together.
Organizations can benefit greatly from clearly established semantic relationships to facilitate data analysis and reporting quickly, support better decision-making processes and foster effective data governance practices.