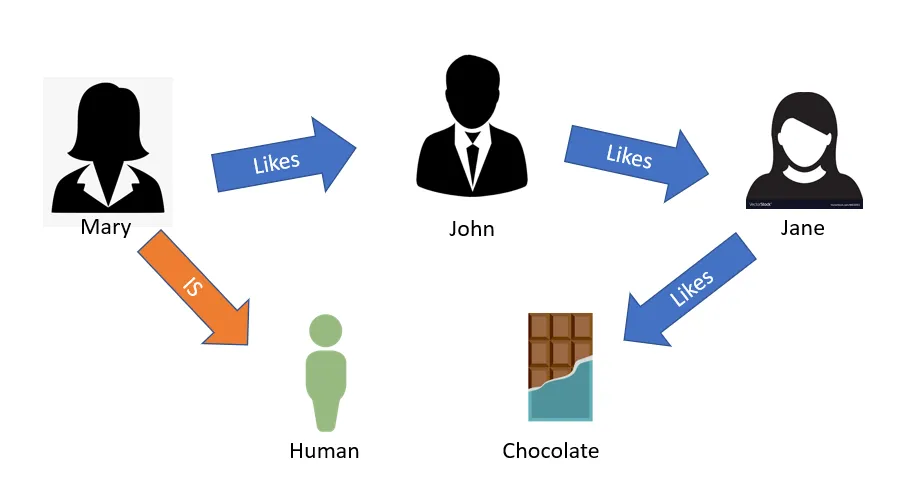
RDF and SPARQL are critical tools for knowledge engineers attempting to manage and analyze data on the semantic web. Understanding these technologies opens doors for working with knowledge graphs and linked data sets more efficiently and meaningfully – increasing efficiency when retrieving it for analysis purposes. As demand for intelligent data systems increases, becoming proficient with RDF (Resource Description Framework) and SPARQL (a query language for RDF) becomes imperative among practitioners working within this sector.
RDF provides an environment for sharing structured data among multiple systems, improving integration and interoperability, while SPARQL makes data retrieval and manipulation possible via queries stored within RDF format. When combined together, knowledge engineers can leverage semantic data for developing sophisticated applications or uncovering insights rooted within it.
Knowledge engineers can leverage semantic web technologies to advance their skillset and contribute to AI-powered data analysis.
Key Takeaways
Key Takeaways
- RDF is a foundational framework for sharing structured data.
- SPARQL allows effective querying and manipulation of RDF data.
- Mastering these tools enhances data integration and analysis in the semantic web.
Understanding RDF: Foundations of Semantic Web Technologies
RDF, or Resource Description Framework, is a key part of the Semantic Web. It is used to model information in a way that computers can understand. RDF helps connect data across different systems, making it easier to share and manage.
Core Concepts and Syntax of RDF
At its core, RDF uses a simple data model based on triples. Each triple consists of a subject, a predicate, and an object.
- Subject: This is the entity being described.
- Predicate: This defines a property or relationship.
- Object: This provides the value or another resource.
For example, in the triple “The sky (subject) is blue (predicate)”. The subject is “The sky”, the predicate describes the information, and the object is “blue”. RDF is often expressed using the Turtle syntax, which is concise and human-readable. Another format is JSON-LD, which integrates RDF with web data.
Serialization Formats and Data Exchange
RDF supports various serialization formats for data exchange. Some popular formats include:
- Turtle: Easy to read and write, ideal for RDF developers.
- RDF/XML: A standard format that uses XML syntax.
- JSON-LD: Integrates linked data into JSON, making it suitable for web applications.
These formats allow RDF data to be stored, shared, and exchanged between systems effortlessly. Standardized formats enhance interoperability, making it easier to link datasets from different sources, which is essential in creating a connected web of data.
RDF Schema and OWL Ontologies
RDF Schema (RDFS) and the Web Ontology Language (OWL) build on RDF to add more structure.
- RDFS: Defines a set of classes and properties. It helps users create vocabularies that describe relationships among data.
- OWL: Adds more complexity, allowing for detailed classification and rules about how data items relate to one another.
RDFS and OWL help create rich ontologies that facilitate linked data. These tools allow knowledge engineers to design complex data frameworks and databases that improve data management and retrieval in RDF technologies.
Mastering SPARQL for Effective Data Retrieval
SPARQL is an essential tool for knowledge engineers working with RDF data. Understanding its structure and capabilities enables users to effectively retrieve and manipulate complex data. This section covers the basics of writing SPARQL queries, advanced techniques, integration with knowledge graphs, and optimization for performance.
Writing Basic SPARQL Queries
Basic SPARQL queries consist of three main components: SELECT, WHERE, and optional clauses.
- SELECT clause specifies the data to return. For example:
SELECT ?book ?author - WHERE clause defines the conditions for retrieving data. It uses patterns to match triples in the RDF store. For instance:
WHERE { ?book rdf:type ex:Book . ?book ex:writtenBy ?author } - Optional clauses like
FILTERandORDER BYcan refine query results further. TheFILTERfunction helps restrict results based on conditions, whileORDER BYsorts the results for better readability. A basic SQL-like familiarity is beneficial, as many concepts parallel those found in SQL.
Advanced Query Features and Techniques
SPARQL 1.1 introduced advanced features like subqueries and aggregation. Subqueries allow users to nest queries within a main query, enhancing flexibility.
Aggregating results can be achieved using functions like COUNT, SUM, or AVG. For example:
SELECT (COUNT(?book) AS ?bookCount)
WHERE { ?book rdf:type ex:Book }
Additionally, OPTIONAL can include data that may not exist for all entities, which is useful for creating comprehensive result sets without losing information. Mastering these features enables better data representation and insight extraction.
Integrating SPARQL with Knowledge Graphs
Integrating SPARQL with knowledge graphs enhances data retrieval by leveraging rich relationships among entities. Knowledge graphs, built on ontologies, provide a structured way to understand data.
Utilizing SPARQL queries on such graphs allows for complex queries that account for relationships between different data points. For instance, querying for authors and their associated books in a knowledge graph can unveil insights into publication trends.
Furthermore, connecting SPARQL to graph databases can improve data efficiency and accessibility. Ensuring proper data representation and relationships in knowledge graphs makes SPARQL queries more powerful and informative.
Performance Optimization and Analytics
For large datasets, performance optimization is crucial. Strategies include query structuring to minimize the size of result sets. Using appropriate indexing on RDF stores can significantly enhance query speed.
Incorporating analytics tools can provide insight into query performance, highlighting slow-running queries and optimizing them. Techniques like caching frequently accessed results can reduce load times.
Using features such as LIMIT and OFFSET helps manage data volumes in results. This approach enables users to paginate results efficiently, allowing for better management of large datasets in SPARQL. These strategies contribute to effective data engineering and knowledge sharing among users.